

How search engines rank pages

Search engines rank websites based on the classification of queries. They assign context and determine which signals are the most important.
As SEO professionals, we often think about how to rank pages.
But, we should also be asking the question, "How do search engines rank pages?"
So Why Do Search Engines Rank Web Pages?
Before we get into the details of how search engines rank web page pages, let's take a moment to think about why they rank these pages.
It would be easier and cheaper for them to display pages randomly by word count, freshness, or any other of a variety of easy sorting systems.
It is easy to see why they don't.
They'd never get any traction from users.
When we ask about rankings, we must remember that the user we're trying to draw to our pages doesn't belong to us.
They belong to the engine, and we are borrowing them.
If we abuse this user, they might not return to the engine.
The engine wouldn't stand for that as their advertising revenue would drop.
That scenario is similar to the pages that we have on our own site.
We recommend tools and services based on our experiences with them.
We believe that they will be useful to our visitors.
We will remove any tool or service that we find not to be useful from our site.
This is what engines do.
But the burning question remains: how do they do it?
A Quick Warning
I don't have any eavesdropping devices on Google or Bing.
This is to clarify that the following outline was based on studying search engines, reviewing patents, as well as starting each day by looking at the industry's happenings from SERP layout changes and acquisitions to algorithm upgrades.
This is an educated breakdown that I hope to get about 85% right.
Easy - Just 5 Steps
The complete ranking of a page requires five steps.
I don't include technical issues like load-balancing, and I'm also not talking about each signal calculation.
I am referring to the core process every query must go through in order to begin its life as an information request, and end it as a group of 10 blue links hidden beneath an ocean of ads.
This process is important to understand. Once you have mastered it, you can begin to think about how to rank the pages of your website for Google's users.
It is also important to mention that these words are my own and not official titles.
You are free to use them, but do not expect all engines to use the exact same terminology.
Step 1 - Classify
The first step is to categorize the query.
The query classification gives the engine all the information it requires to complete the subsequent steps.
This complex classification was not possible before the engines used keywords as entities. Before this, engines applied all signals equally to every query.
This is not the case anymore, as we'll see below.
This is the first stage in which the engine applies such labels (again not a technical term, but a simple way to think about) to queries such as:
YMYL
Local
Unseen
Adult
Question
Although I don't know how many classifications exist, the engine would have to first determine which ones apply to any query.
Step 2 - Context
The second step of the ranking process involves assigning context.
The engine should, whenever possible, consider any information that they may have about the user who has entered the query.
We see personalization and localization happen even when we don't explicitly ask for it. Like this:

This is an example of a query that I didn't enter specifically.
The second stage of the process, essentially, is for the engine to determine which historical and environmental factors are involved.
They are able to identify the type of query and retrieve the pertinent data for it.
Here are some examples of historical and environmental information that might be taken into consideration:
Localization
Time
Is it a question
Device used
The query format
If the query is related to any previous queries
If they've ever seen the question before
Step 3 - Weights
Let me ask you a question before we get started: are you tired of hearing about the magical RankBrain?
Sorry ahead of schedule, but we're going to bring it up again as an example.
Before an engine can rank pages, it must first determine which signals are the most important.
We get the following result for a query "civil war":
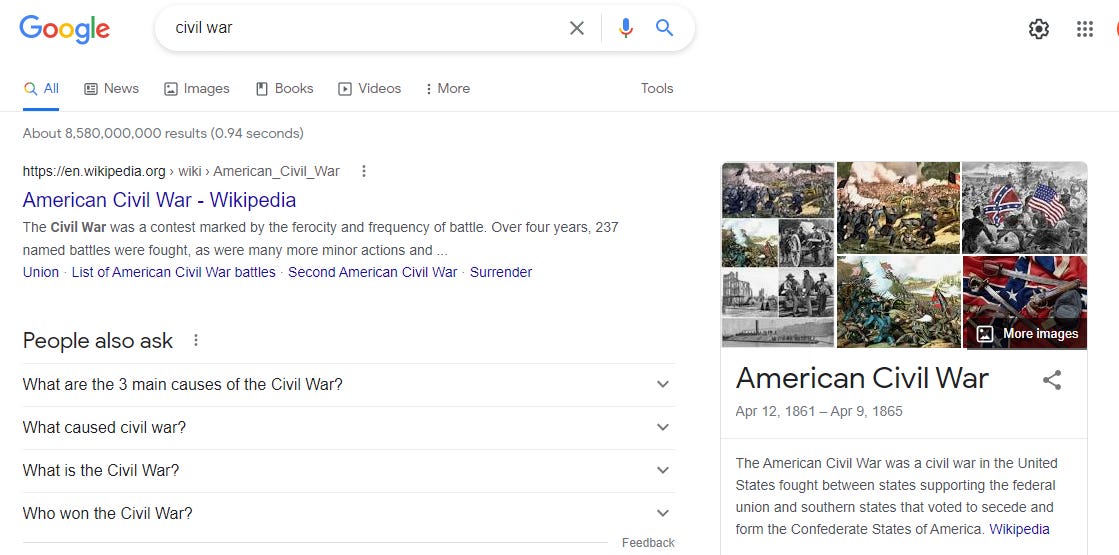
Solid results. What if freshness played a significant role? The result would be more like this:
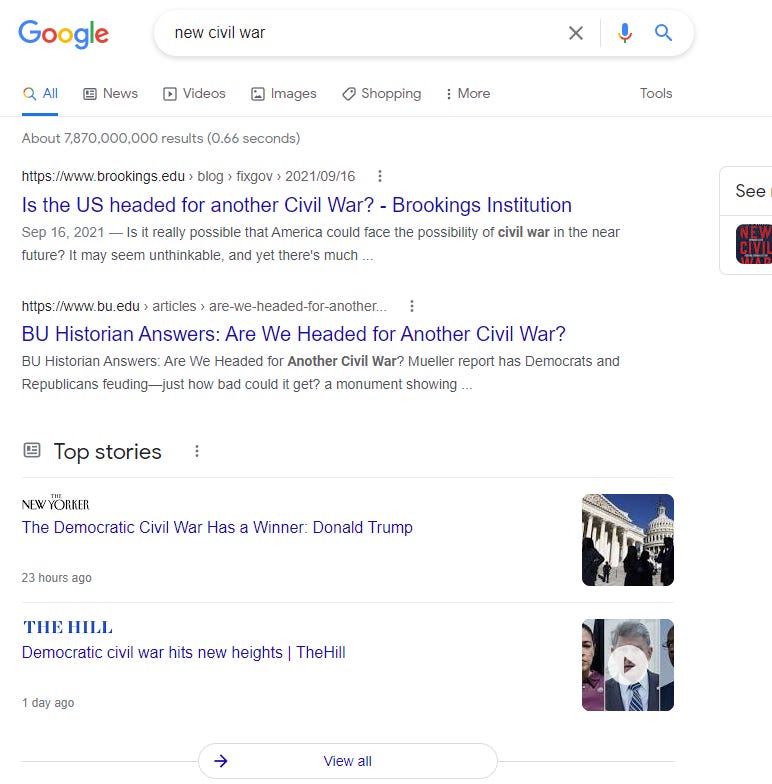
However, freshness is something we cannot rule out.
If the query was "best shows on Netflix", I would care less about its authority and more about when it was published.
A 2008 article that outlines the top DVDs available on their service is a highly linked piece I don't want.
With the query type and context elements in hand, the engine can now rely upon its understanding of which signals apply to which combinations and which weightings.
While some of these tasks can be done manually by talented engineers and computer scientists, a portion of them will be managed by systems such as RankBrain.
This machine-learning algorithm was created to adjust signal weights for previously unresolved queries and later integrated into Google's overall algorithms.
It is reasonable to assume that Bing uses similar systems, given that approximately 90% of its ranking algorithms are based on machine learning.
Step 4 - Layout
It's something we all have seen. It's evident in the civil war example. The search results page layout can change for different queries.
The engines will determine which formats are possible for a query intent, the querying user, and the available resources.
The SERPs are not static targets.
It's formed by knowledge of entities, their connections, and how they are weighted.
This is a complex topic, so we won't get into it (in this article).
It is important to note that search results pages can be sorted more or less on the fly.
This means that after a query has been run and all three steps have been completed, the engine will refer to a database of possible elements to insert onto the page and their possible placements to determine which one will apply to that query.
This would hold true for infrequent queries but it is much more likely that engines have a database of elements that they have calculated to match the user intent to avoid having to process each query.
For the coders out there, this is roughly equivalent to caching. When dealing with vast volumes of information as Google does, it's important to take every step possible to increase speed and responsiveness.
A complete guess here, but I would imagine those cached elements refresh during periods of low usage.
Moving on, the engine knows the classification of the query, the context in which the information is being requested, the signal weights applicable to such a question, and the layout that will most likely meet the various intents for the query.
Let's rank this bad boy.
Step 5 - Ranking
This is, surprisingly, the easiest step in the entire process.
However, it's not as simple as one might think.
The 10 blue links are what we associate with organic rankings. Let's look at the entire process so far.
The user enters a query.
The engine analyzes the type of query to determine what key criteria are applicable at a high level based on similar or identical query interactions in the past.
To determine their most probable intent, the engine will consider freshness and location.
The engine uses the user-specific signals and query classifications to determine what signals should have what weights.
The engine uses the data above to determine what layouts, formats, and other data might satisfy or supplement the user's intent.
All this information is in your hand, and an algorithm has been written.
It's time to crunch the numbers.
They will collect the relevant sites, assign weights to their algorithms, and determine the order in which the sites should appear in search results.
They must do this for every element of the page in different ways.
Videos, stories, and entities change all the time, so engines must order the blue links as well as everything else on the page.
The Summary
It's easy to rank websites.
The behind-the-scenes work is where the real grind happens.
You're probably wondering how the heck all of this is supposed to help you rank your pages.
The analogy I like to use is this.
There are a lot of no-code tools out there, and most of them do a great job of making programming more accessible to the masses.
Great technology is only as strong as its user adoption.
And while you may be just fine not knowing any code, a seasoned programmer that comes along to use a no-code tool will blow you out of the water.
It won't even be close.
Why?
It's likely that they understand the inner mechanisms of the no-code tool you're using.
And since they fundamentally understand the system, they will be faster to invent solutions and solve problems than you.
SEO is no different.
You can certainly win a lot of business and rank pages well without understanding Google's ranking algorithms.
But if you're looking to be a top 1% SEO?
You'll have to understand the technical details behind these systems.
And as your technical understanding increases, your strategies will grow in their effectiveness, making you happier and wealthier.